AI/ML Enhancement Project - Discovering Labelled EO Data with STAC
Introduction
The use of the SpatioTemporal Asset Catalogs (STAC) format is crucial when it comes to search and discover spatio-temporal datasets, including labelled Earth Observation (EO) data. It allows filtering search results using STAC metadata as query parameters, such as spatial and temporal extents, resolution, and other properties. As well as ensuring that the data becomes discoverable and accessible to other stakeholders (e.g. users, researchers, policymakers, etc), the use of STAC brings several other benefits, including enhancing the reproducibility and transparency of the process and its result.
This post presents User Scenario 4 of the AI/ML Enhancement Project, titled “Alice discovers the labelled EO data”. It demonstrates how the enhancements being deployed in the Geohazards Exploitation Platform (GEP) and Urban Thematic Exploitation Platform (U-TEP) will support users exploiting STAC format to discover labelled EO data.
To demonstrate these new capabilities defined in this User Scenario, an interactive Jupyter Notebook is used to guide an ML practitioner, such as Alice, in the process of exploiting the STAC format to discover labelled EO data, including:
- Understanding the STAC format
- Accessing STAC via
STAC BrowserandSTAC API - Connectivity with dedicated S3 storage
Practical examples and commands are displayed to demonstrate how these new capabilities can be used from a Jupyter Notebook.
Understanding STAC
The SpatioTemporal Asset Catalog (STAC) specification was designed to establish a standard, unified language to talk about geospatial data, allowing it to be more easily searchable and queryable. By defining query parameters based on STAC metadata, such as spatial and temporal extents, resolution, and other properties, the user can narrow down a search with only those datasets that align with the specific requirements.
There are four components specifications that together make up the core STAC specification:
-
STAC Item: the core unit representing a single spatiotemporal asset as a
GeoJSONfeature with datetime and links. -
STAC Catalog: a simple, flexible
JSONfile of links that provides a structure to organize and browse STAC Items. -
STAC Collection: an extension of the STAC Catalog with additional information such as the extents, license, keywords, providers, etc., that describe STAC Items that fall within the Collection.
-
STAC API: it provides a RESTful endpoint that enables search of STAC Items, specified in OpenAPI, following OGC’s WFS 3.
A STAC Catalog is used to group STAC objects like Items, Collections, and/or even other Catalogs.
Below are shown some commands of the pystac library that can be used to extract information from a STAC Catalog / Item / Collection.
import pystac
# Read STAC Catalog from file and explore High-Level Catalog Information
cat = Catalog.from_file(url)
cat.describe()
# Print some key metadata
print(f"ID: {cat.id}")
print(f"Title: {cat.title or 'N/A'}")
print(f"Description: {cat.description}")
# Access to STAC Child Catalogs and/or Collections
col = [col for col in cat.get_all_collections()]
# Explore STAC Item Metadata
item = cat.get_item(id=<item_id>, recursive=True)
More information can be found in the official STAC documentation.
Accessing STAC via STAC Browser and STAC API
There are two ways to discover STAC data: by using the STAC Browser or by using the STAC API.
Accessing using STAC Browser
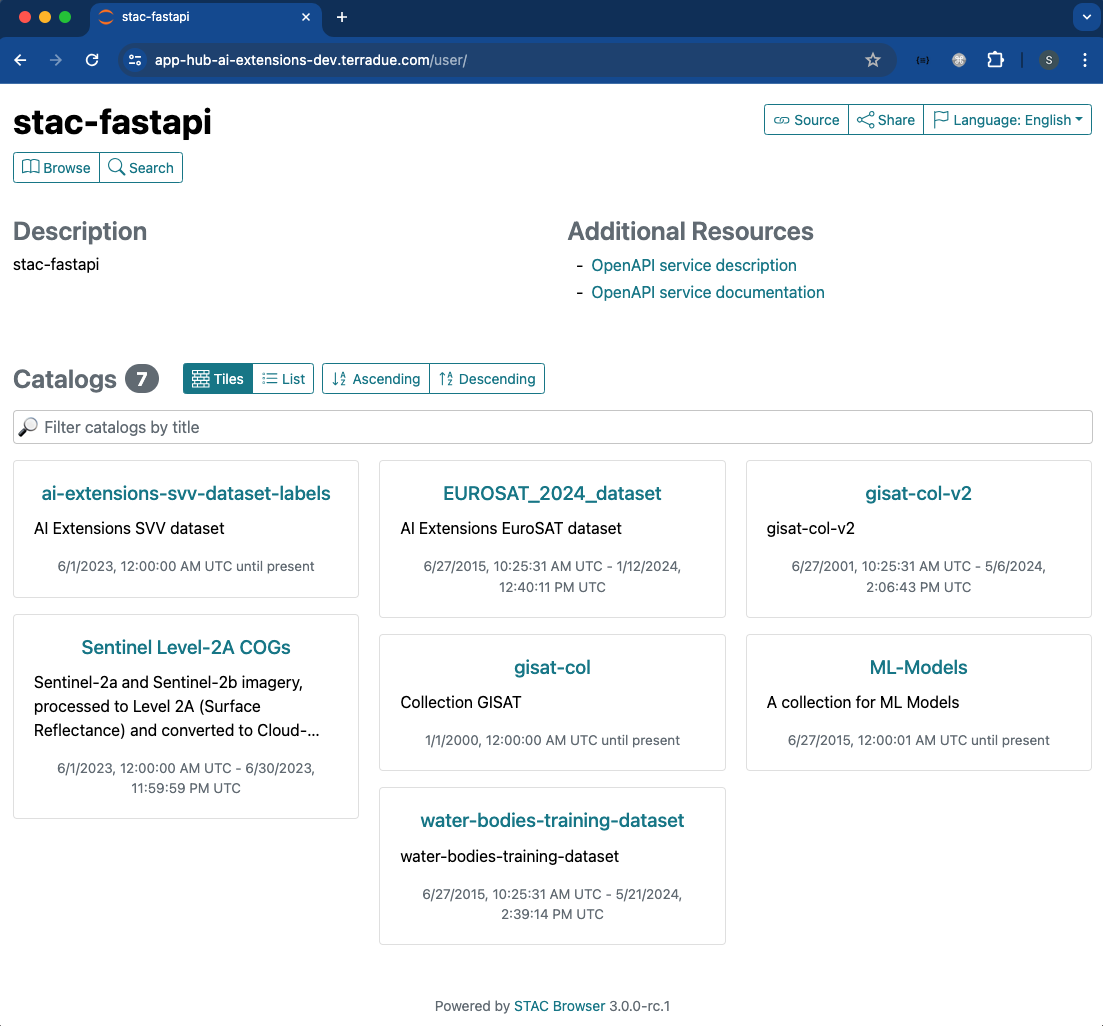
The STAC Browser provides a user-friendly graphical interface that facilitates the search and discovery of datasets. A few screenshots of the graphical interface are provided below.
The dedicated STAC Browser app can be launched by the user at login with the option STAC Browser for AI-Extensions STAC API. The STAC Catalog and Collections available on the App Hub project endpoint will be displayed.
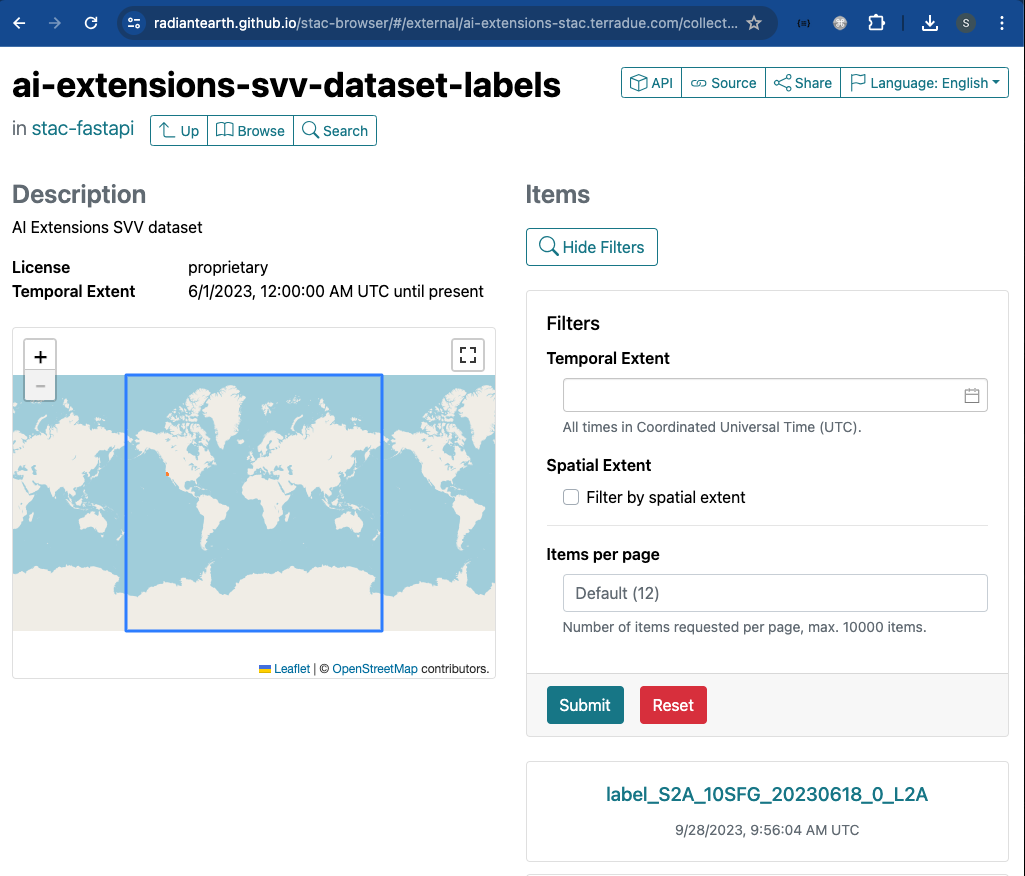
After selecting a specific collection, the query parameters can be manually specified with the dedicated widgets in the Filters section (temporal and spatial extents in this case).
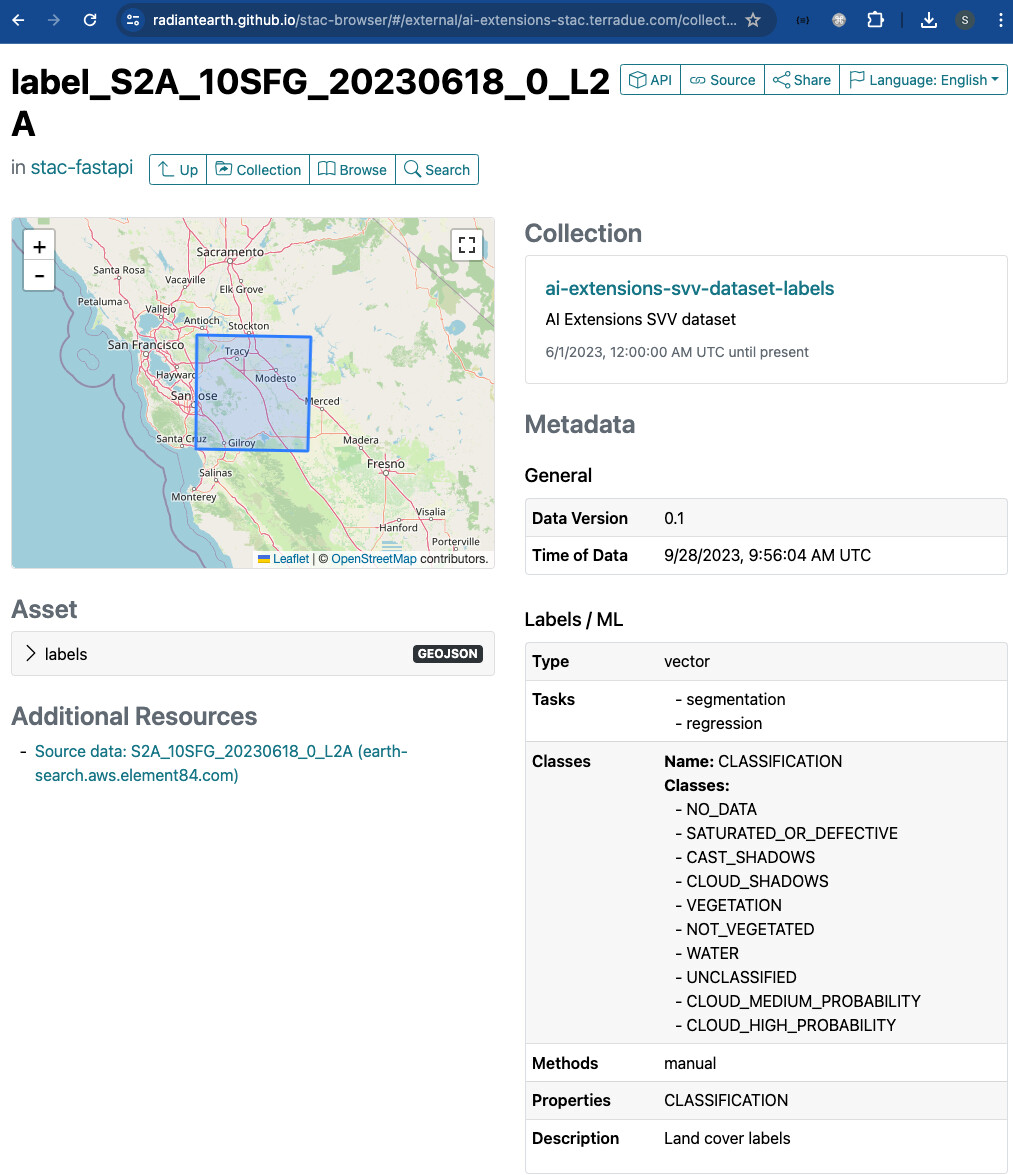
The search results are then shown after clicking Submit. In the example screenshot below, it is shown a single STAC Item with its key metadata.
Despite its user-friendly interface, the use of the STAC Browser is quite limited to manual interactions with the user, making it difficult and time consuming when performing multiple searches with different parameters, for example. For this reason, the use of the STAC Browser is primarily designed for manual exploration and is less suited for automated workflows.
Accessing using STAC API
The STAC API allows for programmatic access to data, enabling automation of data discovery, retrieval, and processing workflows. This is particularly useful for integrating STAC data into larger geospatial data processing pipelines or applications..
import requests
# Define payload for token request
payload = {
"client_id": "ai-extensions",
"username": "ai-extensions-user",
"password": os.environ.get("IAM_PASSWORD"),
"grant_type": "password",
}
auth_url = 'https://iam-dev.terradue.com/realms/ai-extensions/protocol/openid-connect/token'
token = get_token(url=auth_url, **payload)
headers = {"Authorization": f"Bearer {token}"}
Once the authentication credentials are defined, the private STAC Catalog can be accessed and searched using specific query parameters, such as time range, area of interest, and data collection preferences. Subsequently, only the STAC Item(s) that align with the provided criteria is(are) retrieved for the user. This can be achieved with the pystac and pystac_client libraries.
# Import libraries
import pystac
from pystac_client import Client
# Define STAC endpoint and access to the Catalog
stac_endpoint = "https://ai-extensions-stac.terradue.com"
cat = Client.open(stac_endpoint, headers=headers, ignore_conformance=True)
# Define query parameters
start_date = datetime.strptime(“20230601”, '%Y%m%d')
end_date = datetime.strptime(“20230630”, '%Y%m%d')
bbox = [-121.857043 37.853934 -120.608968 38.840424]
tile = “10SFH”
# Query by AOI, start and end date
query_sel = cat.search(
collections=[“ai-extensions-svv-dataset-labels”],
datetime=(start_date, end_date),
bbox=bbox,
)
item = [item for item in query_sel.item_collection() if tile in item.id][0]
# Display Item
display(item)

Connectivity with dedicated S3 storage
Up until now the user accessed the STAC endpoint for exploring the Catalog and its Collections / Items. In this section we describe the process to access the data referenced in the Item’s assets, which are stored in a dedicated S3 bucket.
The AWS S3 configuration settings are defined in a .json file (eg appsettings.json), which is used to create a UserSettings object. This will be used to create a configured S3 client to retrieve an object stored on S3, using boto3 and botocore libraries.
# Import libraries
import botocore, boto3
# Define AWS S3 settings
settings = UserSettings("appsettings.json")
settings.set_s3_environment(<asset_s3_path>)
# Start botocore session
session = botocore.session.Session()
# create client obj
s3_client = session.create_client(
service_name="s3",
region_name=os.environ.get("AWS_REGION"),
use_ssl=True,
endpoint_url=os.environ.get("AWS_S3_ENDPOINT"),
aws_access_key_id=os.environ.get("AWS_ACCESS_KEY_ID"),
aws_secret_access_key=os.environ.get("AWS_SECRET_ACCESS_KEY"),
)
parsed = urlparse(geojson_url)
# retrieve bucket name
bucket = parsed.netloc
key = parsed.path[1:]
# retrive the obj which was stored on s3
response = s3_client.get_object(Bucket=bucket, Key=key)
The user can then download locally the file stored on S3 using io library.
import io
geojson_content = io.BytesIO(respond["Body"].read())
fname = './output/downloaded.geojson'
# Save the GeoJSON content to a local file
with open(fname, "wb") as file:
file.write(geojson_content.getvalue())
The user can also import the downloaded data into this Notebook. In this example, the downloaded .geojson file is loaded and converted into a pandas dataframe.
import geopandas as gpd
# Make geodataframe out of the downloaded .geojson file
gdf = gpd.read_file(fname)
gdf
Conclusion
This work demonstrates the new functionalities brought by the AI/ML Enhancement Project to help a ML practitioner exploiting the STAC format to discover labelled EO data, including:
- Understanding the STAC format
- Accessing STAC via
STAC BrowserandSTAC API - Connectivity with dedicated S3 storage
Useful links:
- The link to the Notebook for User Scenario 4 is: https://github.com/ai-extensions/notebooks/blob/develop/scenario-4/s4-discoveringLabelledEOData.ipynb
Note: access to this Notebook must be granted - please send an email to support@terradue.com with subject “Request Access to s4-discoveringLabelledEOData” and body “Please provide access to Notebook for AI Extensions User Scenario 4” - The user manual of the AI/ML Enhancement Project Platform is available at AI-Extensions Application Hub - User Manual
- Project Update “AI/ML Enhancement Project - Progress Update”
- User Scenario 1 “AI/ML Enhancement Project - Exploratory Data Analysis”
- User Scenario 2 “AI/ML Enhancement Project - Labelling EO Data”
- User Scenario 3 “AI/ML Enhancement Project - Describing labelled EO data”