AI/ML Enhancement Project - Training and Inference on a remote machine
Introduction
In this scenario, the ML practitioner Alice develops two Earth Observation (EO) Application Packages using the Common Workflow Language (CWL), as described in the OGC proposed best practices. The two App Packages CWLs are executed on a remote machine with a CWL runner for Kubernetes, enabling the submission of (parallel) kubernetes jobs distributed across the available resources in the cluster. MLflow is used for tracking experiments and related metrics for further analysis and comparison.
- App Package CWL for a training job: Alice develops an ML training job with Random Forest, based on a segmentation approach for water bodies masking. The training process is repeated and evaluated for each training run with MLflow and in the end, the model evaluated with higher performance is selected and used for the inference service.
- App Package CWL for inference job: this service performs inference on Sentinel-2 data, based on the best model developed with the training service. It takes as input parameter the STAC Item(s) of Sentinel-2 data and generates the inference water-bodies output mask(s).
This post presents User Scenario 6 of the AI/ML Enhancement Project, titled “Alice starts a training job on a remote machine”. It demonstrates how the enhancements being deployed in the Geohazards Exploitation Platform (GEP) and Urban Thematic Exploitation Platform (U-TEP) will support users on packaging EO applications using CWL format and for using a CWL runner for executing and managing Kubernetes jobs.
These new capabilities are implemented through the development and execution of the two App Packages CWLs to guide an ML practitioner, such as Alice, through the following steps:
- Write a Python application with its containerised environment
- Use the CWL standard, as described in the OGC proposed best practices, for writing EO Application Packages
- Dockerise all processing nodes and write the App Package CWLs through CI/CD pipeline with GitHub Actions, and release them as official repository releases
- Use the CWL runners for Kubernetes to submit (parallel) jobs, distributing them across the available resources in the cluster
- Configure MLflow server for tracking the experiments and log relevant information
Practical examples and commands are displayed to demonstrate how these new capabilities can be used within the App Hub environment.
Key Concepts
Common Workflow Language
The Common Workflow Language (CWL) is a powerful community-driven standard for describing, executing and sharing computational workflows. Originating from the bioinformatics community, CWL has gained traction across various scientific disciplines, including the EO sector.
The CWL standard supports multiple workflows and includes two key components (i.e. classes):
Workflowclass/standard for describing workflows: in this class are defined all input parameters and the final output of the application. The processing steps are defined with only the inputs specific to each step, and the dependencies between steps are established by defining the output(s) of one step as the input(s) of another step. Thescatteris a feature that enables parallel execution of tasks based on specific inputs and is defined at step level.CommandLineToolclass/standard for describing command line tools: in this class are defined the inputs and arguments needed for each specific module, the environment variables (EnvVarRequirement), the docker container in which the module is executed (DockerRequirement), the specific resources allocated for its execution (ResourceRequirement), and the type of output generated.
A simple guide on how to get started on EO Application Packages with CWL is provided here.
Kubernetes
Kubernetes is an open-source container orchestration engine designed to automate the deployment, scaling, and management of containerized applications. It provides a robust framework to run distributed systems efficiently, ensuring high availability and scalability.
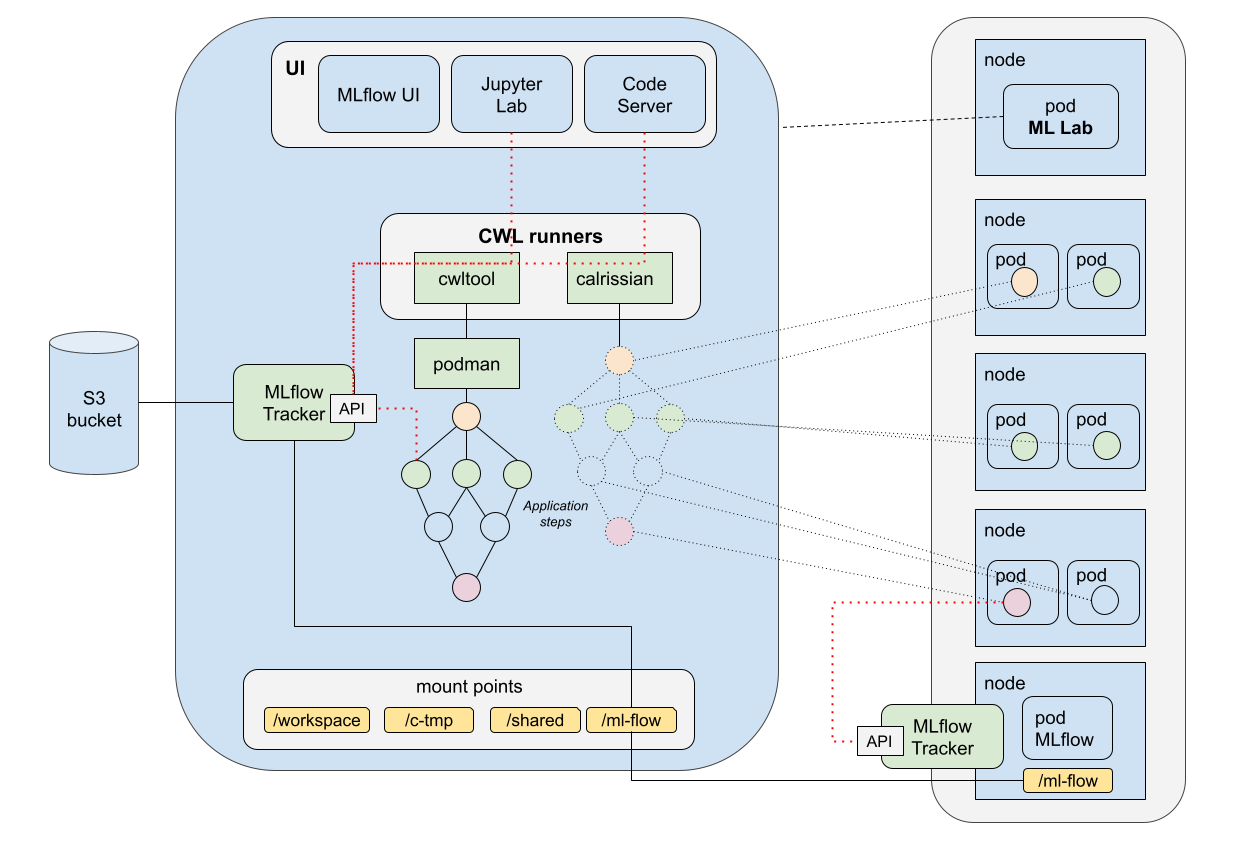
The development environment ML Lab runs on a Kubernetes cluster composed of multiple nodes. When a user starts their own ML Lab pod, this is instantiated using one of the available nodes, based on the resource requirements of the specific user pod. From within the ML Lab pod, the user can use two CWL runners to execute an Application Package CWL:
- Using
cwltool, the CWL is executed using the Kubernetes node that hosts the ML Lab user pod. This is done withpodman, an open-source tool for Linux for managing containerized applications. - Using
calrissian, the CWL runner creates pods leveraging all the nodes available on the Kubernetes cluster. The Kubernetes cluster autoscaler facilitates this behaviour by creating new nodes on demand to satisfy all the requests made bycalrissian. The vertical architecture ofcalrissianmakes it ideal for running large-scale workflows in a cloud or high-performance computing environment.
The implementation of both CWL runners cwltool and calrissian from the ML Lab user pod is shown in the diagram below.
App Package CWL for training job
Objective
The training job consists of a Random Forest model based on a segmentation approach for water bodies masking on EO data.
Application Workflow
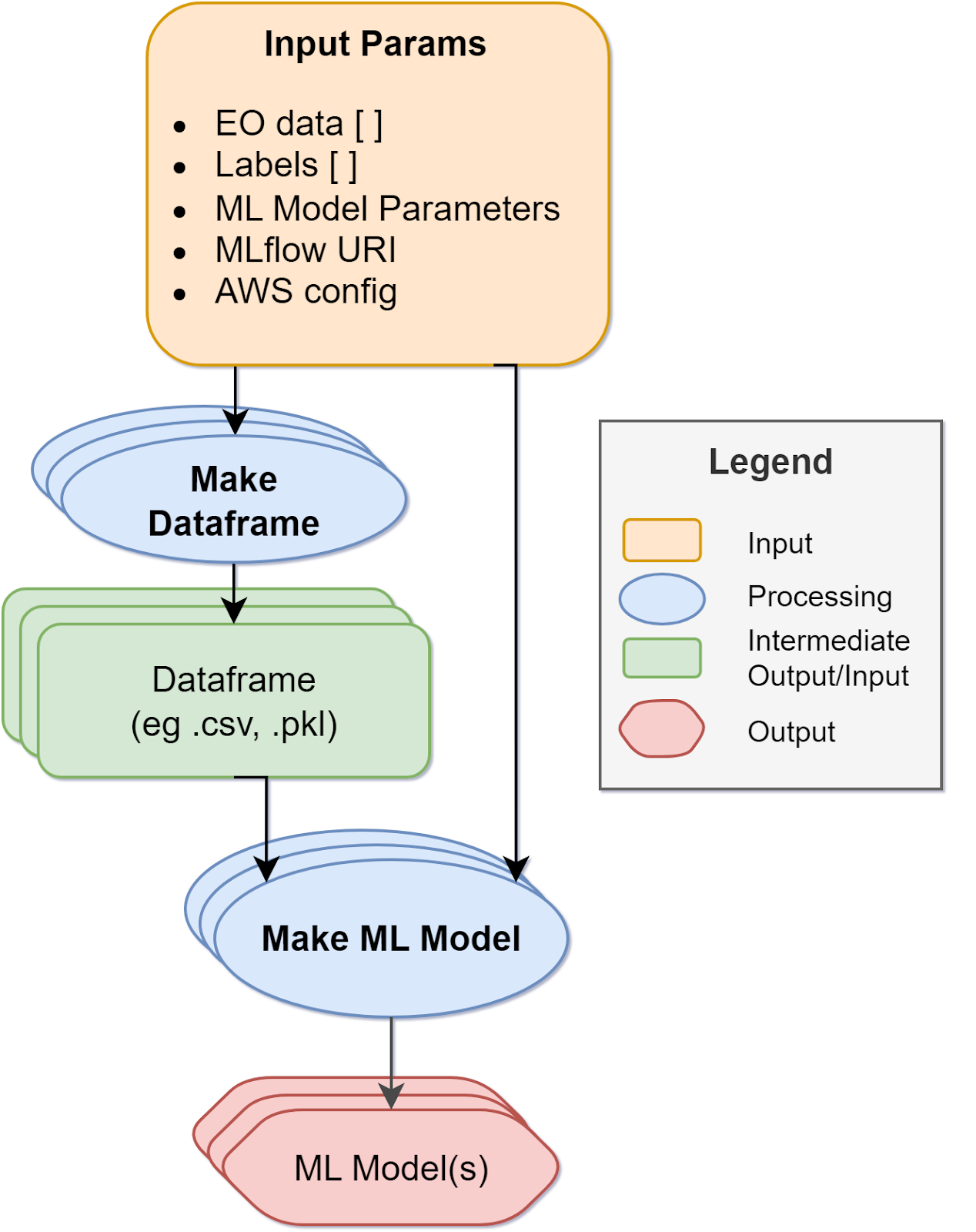
The workflow of the Application Package for the training job is illustrated in the diagram below.
Application Inputs
The inputs are:
- STAC Item(s) of EO Data (Sentinel-2)
- STAC Item(s) of EO Labels
- ML model parameters (e.g.
RANDOM_STATEandn_estimators) - MLflow URL
- AWS-related configuration settings
Application Outputs
The expected output is:
- ML Model(s) saved and tracked with MLflow on the configured MLflow server
Processing Modules
The training workflow is structured in two processing modules:
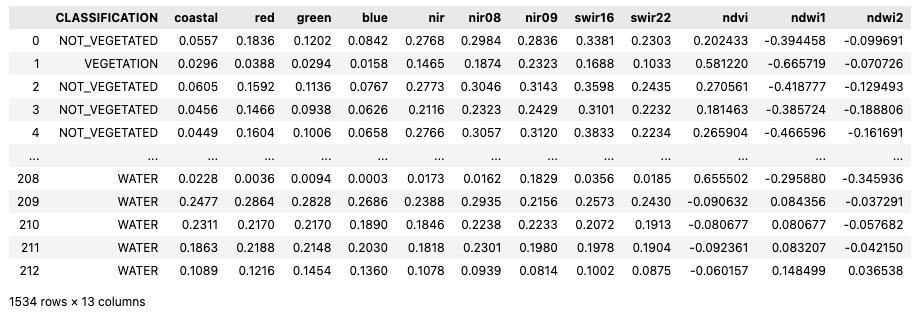
make-dataframefor creating dataframes (e.g..pklfile) based on EO data sampling on the classified EO labels. This consisted in extracting the reflectance values of the EO bandscoastal,red,green,blue,nir,nir08,nir09,swir16, andswir22in correspondence of each EO label point, in addition to its classified label. Subsequently, the three vegetation indicesndvi,ndwi1, andndwi2are calculated from a selection of these EO bands. This approach is described more in detail with its Python code in the “Sample EO data with labels” function described in the related article “Labelling EO Data User Scenario 2”. The output of this module is a list of dataframes with classified EO labels and related spectral values and vegetation indices, as can be seen below.
make-ml-modelfor initiating, training and evaluating multiple ML models based on the input dataframes and the input ML model parameters. The list of generated dataframes are firstly merged into a unique dataframe, which is then split intotrain,validationandtestsets. Subsequently, a number of estimators (based on the user input) are trained using aRandomForestclassifier with the k-fold cross-validation method. The candidate model is chosen based on the accuracy of these estimators on the test dataset. Finally, the best estimator is evaluated using various metrics, includingaccuracy,recall,precision,f1-score, and the confusion matrix.- All the generated ML models are tracked using MLflow and the artifacts of the training jobs are stored on a dedicated S3 bucket.
Both modules are developed as Python projects, with dedicated source code, environment.yml, Dockerfile and set-up configuration instructions. A Python project template can be found on the guidance document “Setup of software project template for my Python application”.
Application Package CWL
An extraction of the App Package CWL for the training job is shown below, where the following key components can be inspected:
- Class
Workflow: this includes all input parameters and the output of the application. The two processing steps are defined with their specific inputs and outputs dependencies, and thescattermethod is applied to some inputs for parallel execution. - Class
CommandLineToolfor the base commandmake-dataframe: in this class are defined the inputs needed for themake-dataframemodule, the environment variables (EnvVarRequirement), the docker container in which it is executed (DockerRequirement), the specific resources allocated for its execution (ResourceRequirement), and the type of output generated. - Class
CommandLineToolfor the base commandmake-ml-model: this class has the specifications described above but tailored to the needs of this step. In addition, in theargumentssection are also defined, in JavaScrip (InlineJavascriptRequirement), how multiple inputs are handled by this module.
cwlVersion: v1.2
$namespaces:
s: https://schema.org/
s:softwareVersion: 1.0.8
schemas:
- http://schema.org/version/9.0/schemaorg-current-http.rdf
$graph:
- class: Workflow
id: water-bodies-app-training
label: Water-Bodies Training on Sentinel-2 data
doc: Training a RandomForest calssifier on Sentinel-2 data to detect water bodies, and track it using MLFlow.
requirements:
- class: InlineJavascriptRequirement
- class: ScatterFeatureRequirement
inputs:
ADES_AWS_S3_ENDPOINT:
label: ADES_AWS_S3_ENDPOINT
type: string?
ADES_AWS_REGION:
label: ADES_AWS_REGION
type: string?
ADES_AWS_ACCESS_KEY_ID:
label: ADES_AWS_ACCESS_KEY_ID
type: string?
ADES_AWS_SECRET_ACCESS_KEY:
label: ADES_AWS_SECRET_ACCESS_KEY
type: string?
labels_url:
label: labels_url
doc: STAC Item label url
type: string[]
eo_url:
label: eo_url
doc: STAC Item url to sentinel-2 eo data
type: string[]
MLFLOW_TRACKING_URI:
label: MLFLOW_TRACKING_URI
doc: URL for MLFLOW_TRACKING_URI
type: string
RANDOM_STATE:
label: RANDOM_STATE
doc: RANDOM_STATE
type: int[]
n_estimators:
label: n_estimators
doc: n_estimators
type: int[]
experiment_id:
label: experiment_id
doc: experiment_id
type: string
outputs:
- id: artifacts
outputSource:
- make_ml_model/artifacts
type: Directory[]
steps:
create_datafram:
run: "#create_datafram"
in:
labels_url: labels_url
eo_url: eo_url
ADES_AWS_S3_ENDPOINT: ADES_AWS_S3_ENDPOINT
ADES_AWS_REGION: ADES_AWS_REGION
ADES_AWS_ACCESS_KEY_ID: ADES_AWS_ACCESS_KEY_ID
ADES_AWS_SECRET_ACCESS_KEY: ADES_AWS_SECRET_ACCESS_KEY
out:
- dataframe
scatter:
- labels_url
- eo_url
scatterMethod: dotproduct # "flat_crossproduct" to analyse all possible combination of inputs
make_ml_model:
run: "#make_ml_model"
in:
MLFLOW_TRACKING_URI: MLFLOW_TRACKING_URI
labels_urls: labels_url
eo_urls: eo_url
RANDOM_STATE: RANDOM_STATE
n_estimators: n_estimators
experiment_id: experiment_id
data_frames:
source: create_datafram/dataframe
out:
- artifacts
scatter:
- RANDOM_STATE
- n_estimators
scatterMethod: dotproduct # "flat_crossproduct" to analyse all possible combination of inputs
- class: CommandLineTool
id: create_datafram
requirements:
InlineJavascriptRequirement: {}
NetworkAccess:
networkAccess: true
EnvVarRequirement:
envDef:
PATH: /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/home/linus/conda/envs/env_make_df/bin:/home/linus/conda/envs/env_make_df/snap/bin
AWS_S3_ENDPOINT: $( inputs.ADES_AWS_S3_ENDPOINT )
AWS_REGION: $( inputs.ADES_AWS_REGION )
AWS_ACCESS_KEY_ID: $( inputs.ADES_AWS_ACCESS_KEY_ID )
AWS_SECRET_ACCESS_KEY: $( inputs.ADES_AWS_SECRET_ACCESS_KEY )
ResourceRequirement:
coresMax: 1
ramMax: 1600
hints:
DockerRequirement:
dockerPull: ghcr.io/ai-extensions/make_dataframe:latest
"cwltool:Secrets":
secrets:
- ADES_AWS_ACCESS_KEY_ID
- ADES_AWS_SECRET_ACCESS_KEY
- ADES_AWS_S3_ENDPOINT
- ADES_AWS_REGION
baseCommand: ["make-dataframe"]
arguments: []
inputs:
ADES_AWS_S3_ENDPOINT:
type: string?
inputBinding:
prefix: --AWS_S3_ENDPOINT
ADES_AWS_REGION:
type: string?
inputBinding:
prefix: --AWS_REGION
ADES_AWS_ACCESS_KEY_ID:
type: string?
inputBinding:
prefix: --AWS_ACCESS_KEY_ID
ADES_AWS_SECRET_ACCESS_KEY:
type: string?
inputBinding:
prefix: --AWS_SECRET_ACCESS_KEY
labels_url:
type: string
inputBinding:
prefix: --labels_url
eo_url:
type: string
inputBinding:
prefix: --eo_url
outputs:
dataframe:
outputBinding:
glob: .
type: Directory
- class: CommandLineTool
id: make_ml_model
hints:
DockerRequirement:
dockerPull: ghcr.io/ai-extensions/make_ml_model:latest
baseCommand: ["make-ml-model"]
inputs:
labels_urls:
type: string[]
eo_urls:
type: string[]
MLFLOW_TRACKING_URI:
type: string
inputBinding:
prefix: --MLFLOW_TRACKING_URI
data_frames:
type: Directory[]
RANDOM_STATE:
type: int
inputBinding:
prefix: --RANDOM_STATE
n_estimators:
type: int
inputBinding:
prefix: --n_estimators
experiment_id:
type: string
inputBinding:
prefix: --experiment_id
arguments:
- valueFrom: |
${
var args=[];
for (var i = 0; i < inputs.data_frames.length; i++)
{
args.push("--data_frames");
args.push(inputs.data_frames[i].path);
}
return args;
}
- valueFrom: |
${
var args=[];
for (var i = 0; i < inputs.labels_urls.length; i++)
{
args.push("--labels_urls");
args.push(inputs.labels_urls[i]);
}
return args;
}
- valueFrom: |
${
var args=[];
for (var i = 0; i < inputs.eo_urls.length; i++)
{
args.push("--eo_urls");
args.push(inputs.eo_urls[i]);
}
return args;
}
outputs:
artifacts:
outputBinding:
glob: .
type: Directory
requirements:
InlineJavascriptRequirement: {}
NetworkAccess:
networkAccess: true
EnvVarRequirement:
envDef:
MLFLOW_TRACKING_URI: $(inputs.MLFLOW_TRACKING_URI )
MLFLOW_VERSION: 2.10.0
ResourceRequirement:
coresMax: 1
ramMax: 3000
App Package CWL Execution
For the execution of an App Package workflow are needed the App Package CWL file and the params.yml file containing the input parameters. An example of the params.yml file for the training job is shown below, followed by the executing commands with the CWL runners cwltool and calrissian.
params.yml
ADES_AWS_S3_ENDPOINT: # fill with AWS_S3_ENDPOINT
ADES_AWS_REGION: # fill with AWS_REGION
ADES_AWS_ACCESS_KEY_ID: # fill with AWS_ACCESS_KEY_ID
ADES_AWS_SECRET_ACCESS_KEY: # fill with AWS_SECRET_ACCESS_KEY
labels_url:
- https://ai-extensions-stac.terradue.com/collections/ai-extensions-svv-dataset-labels/items/label_S2A_10SFG_20230618_0_L2A
- https://ai-extensions-stac.terradue.com/collections/ai-extensions-svv-dataset-labels/items/label_S2B_10SFG_20230613_0_L2A
eo_url:
- https://earth-search.aws.element84.com/v1/collections/sentinel-2-l2a/items/S2A_10SFG_20230618_0_L2A
- https://earth-search.aws.element84.com/v1/collections/sentinel-2-l2a/items/S2B_10SFG_20230613_0_L2A
MLFLOW_TRACKING_URI: http://ml-flow-dev-mlflow:5000
RANDOM_STATE:
- 20
- 13
- 19
n_estimators:
- 120
- 150
- 250
experiment_id: "water-bodies"
Execution with cwltool
cwltool is used for the CWL execution on a single Kubernetes node. Note that this approach needs the user to login into the ghcr.io registry where the docker images are saved, to ensure the docker accessibility during the cwltool execution.
podman login ghcr.io
<enter username and password>
cwltool –-podman --no-read-only water-bodies-app-training.cwl#water-bodies-app-training params.yml
Execution with calrissian
calrissian is used for the CWL execution on distributed nodes which is ideal for running large-scale workflows in a cloud or high-performance computing environment.
calrissian --debug --outdir /calrissian --max-cores 2 --max-ram 12G --tmp-outdir-prefix /calrissian --tmpdir-prefix /calrissian --stderr /calrissian/run.log --tool-logs-basepath /calrissian/ water-bodies-app-training.cwl#water-bodies-app-training params.yml
Selection of the best model for inference module
The user can use a Jupyter Notebook to get the best trained model using the mlflow Python library, and save it within the inference module in an .onnx format using the skl2onnx library. This allows the inference module, described below, to run independently from the training module.
# Import Libraries
import mlflow
import pickle
import onnx
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
import rasterio
import pystac
# Search for the best run
active_runs = (
mlflow.search_runs(
experiment_names=[params["experiment_id"]],
# Select the best one with highest f1_score and test accuracy
filter_string="metrics.f1_score > 0.8 AND metrics.test_accuracy > 0.98",
search_all_experiments=True,
)
.sort_values(
by=["metrics.f1_score", "metrics.test_accuracy", "metrics.precision"],
ascending=False,
)
.reset_index()
.loc[0]
)
artifact_path = json.loads(active_runs["tags.mlflow.log-model.history"])[0]["artifact_path"]
best_model_path = active_runs.artifact_uri + f"/{artifact_path}"
# Load the model as an MLflow PyFunc model
mlflow_model = mlflow.pyfunc.load_model(model_uri=best_model_path)
# Extract the underlying scikit-learn model
sklearn_model = mlflow.sklearn.load_model(model_uri=best_model_path)
# Define input type and convert the scikit-learn model to ONNX format
initial_type = [("float_input", FloatTensorType([None, len(features)]))]
onnx_model = convert_sklearn(sklearn_model, initial_types=initial_type)
# Save the ONNX model to a file
onnx.save_model(onnx_model, f"{model_path}")
App Package CWL for inference job
Objective
The inference job consists of performing inference on EO data using the trained Random Forest model for the detection of water bodies.
Application Workflow
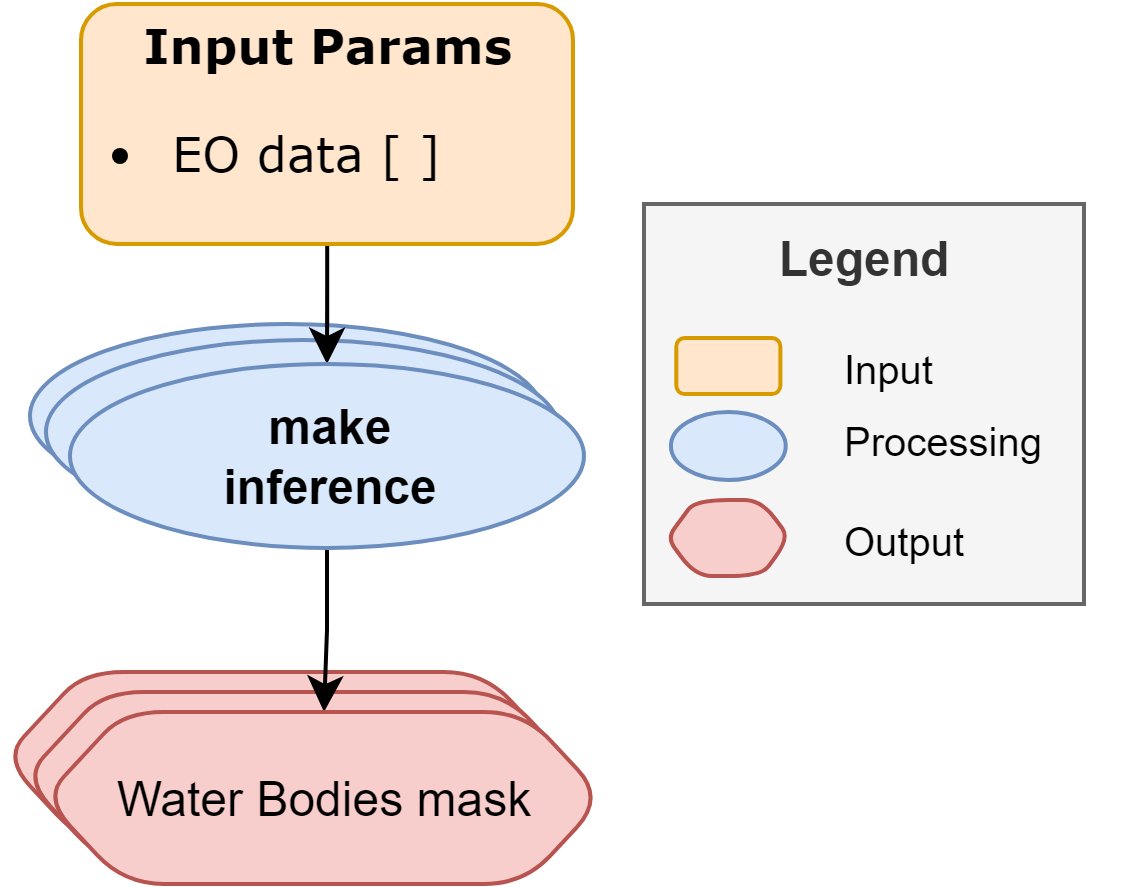
The workflow of the Application Package for the inference job is illustrated in the diagram below.
Application Inputs
The inputs are:
- STAC Item(s) of EO Data (Sentinel-2)
Application Outputs
The expected output is, for each EO Data input, a directory containing:
- water bodies mask (in
.tifformat) with three classes (water,non-waterandcloud) - overview (in
.tifformat) with three classes (water,non-waterandcloud) - STAC Objects
Processing Modules
The inference workflow consists of a single processing module:
make-inferencefor performing inference on a (list of) Sentinel-2 data by applying theRandomForestmodel that was trained and selected during the training job.
Application Package CWL
An extraction of the App Package CWL for the inference job is shown below, where the following key components can be inspected:
- Class
Workflow: in this class are defined the input parameter (i.e. the list of Sentinel-2 data) and the output of the application. The single processing stepmake-inferencescatters its execution based on the Sentinel-2 data input. - Class
CommandLineToolfor the base commandmake-inference: in this class are defined the inputs needed for themake-inferencemodule, the docker container in which it is executed (DockerRequirement), the specific resources allocated for its execution (ResourceRequirement), and the type of output generated.
cwlVersion: v1.2
$namespaces:
s: https://schema.org/
s:softwareVersion: 1.0.9
schemas:
- http://schema.org/version/9.0/schemaorg-current-http.rdf
$graph:
- class: Workflow
id: water-bodies-app-inference
label: Water-Bodies Inference on Sentinel-2 data
doc: A trained Random Forest model performs inference on Sentinel-2 data to detect water bodies
requirements:
- class: InlineJavascriptRequirement
- class: ScatterFeatureRequirement
inputs:
s2_item:
label: s2_item
doc: s2_item
type: string[]
outputs:
- id: artifacts
outputSource:
- make_inference/artifacts
type: Directory[]
steps:
make_inference:
run: "#make_inference"
in:
s2_item: s2_item
out:
- artifacts
scatter:
- s2_item
scatterMethod: dotproduct
- class: CommandLineTool
id: make_inference
hints:
DockerRequirement:
dockerPull: ghcr.io/ai-extensions/water-bodies-inference:latest
baseCommand: ["make-inference"]
inputs:
s2_item:
type: string
inputBinding:
prefix: --s2_item
outputs:
artifacts:
outputBinding:
glob: .
type: Directory
requirements:
InlineJavascriptRequirement: {}
NetworkAccess:
networkAccess: true
ResourceRequirement:
coresMax: 1
ramMax: 3000
App Package CWL Execution
An example of the params.yml file for inference job is shown below, followed by the commands to execute the App Package CWL with cwltool and calrissian.
params.yml
s2_item:
- https://earth-search.aws.element84.com/v1/collections/sentinel-2-l2a/items/S2A_10SFG_20230618_0_L2A
- https://earth-search.aws.element84.com/v1/collections/sentinel-2-l2a/items/S2B_10SFG_20230613_0_L2A
Execution with cwltool
cwltool –-podman --no-read-only water-bodies-app-inference.cwl#water-bodies-app-inference params.yml
Execution with calrissian
calrissian --debug --outdir /calrissian/ --max-cores 2 --max-ram 12G --tmp-outdir-prefix /calrissian/ --tmpdir-prefix /calrissian/ --stderr /calrissian/run.log --tool-logs-basepath /calrissian/ water-bodies-app-inference.cwl#water-bodies-app-inference params.yml
Conclusion
This work demonstrates the new functionalities brought by the AI/ML Enhancement Project to guide a ML practitioner through the development and execution of the two App Packages CWLs, including the following activities:
- Write a Python application with its containerised environment
- Use the CWL standard for writing EO Application Packages
- Dockerise all processing nodes and write the App Package CWLs through CI/CD pipeline with GitHub Actions
- Use the CWL runners for Kubernetes to submit (parallel) training jobs as kubernetes jobs, distributing them across the available resources in the cluster
- Configure MLflow server for tracking the experiments and log relevant information
Useful links:
- The link to the repository where both training and inference jobs are saved is: https://github.com/ai-extensions/notebooks/tree/main/scenario-6/
Note: access to this repository must be granted - please send an email to support@terradue.com with subject “Request Access to s6-repository” and body “Please provide access to the repository for AI Extensions User Scenario 6” - The user manual of the AI/ML Enhancement Project Platform is available at AI-Extensions Application Hub - User Manual
- Project Update “AI/ML Enhancement Project - Progress Update”
- User Scenario 1 “Exploratory Data Analysis”
- User Scenario 2 “Labelling EO Data”
- User Scenario 3 “Describing labelled EO data”
- User Scenario 4 “Discovering labelled EO data with STAC”
- User Scenario 5 “Developing a new ML model and tracking with MLflow”